Bad Code, Real Revenue: How to Rescue a System You Can’t Turn Off

Your system is making money. Customers are paying. The business depends on it.
But every time the team fixes one bug, something else breaks. Delivery slows. Reliability? You haven’t heard that word in ages. Maintenance begins consuming more engineering attention than anyone is comfortable admitting. What once looked like a manageable technical problem starts dictating the pace of the business.
This is a common pattern in growing companies. The code that supports revenue today can quietly become the thing that blocks growth tomorrow. In practice, this is one of the four hidden bottlenecks behind underperforming IT teams, and the one that shows up earliest in the financials.
The good news is that you usually do not have to choose between tolerating the mess and shutting the system down for a rewrite. In many cases, there is a more deliberate path: stabilize what matters, reduce risk, and modernize in stages while the business keeps operating.
Why Revenue-Critical Systems Become Hard to Change
Once a messy system starts generating meaningful revenue, it stops being only a technical problem. It becomes an operational dependency.
More customers, more transactions, and more workflows increase the blast radius of every change. A bug no longer affects only one feature. It can affect billing, onboarding, support operations, reporting, or retention. That changes how the business behaves: leadership becomes more risk-averse, teams start patching instead of improving, and deeper fixes get postponed because they feel harder to justify than another short-term workaround.
The technical side makes this worse, though not in every case. These problems tend to compound in systems that were designed poorly and then kept alive through constant patching. When the team is under pressure to fix the next issue, test coverage lags behind, documentation never catches up, and critical knowledge stays concentrated in a few people. The business side locks the system in even further: customers rely on it, downtime is expensive, and there is rarely an appetite for a full replacement unless things are already going badly.
That is how a revenue-critical system turns into a trap. It still works well enough to stay alive, but not well enough to scale safely.
The Business Cost of Living with Bad Code
Poor code quality does not just slow developers down. It affects reliability, delivery predictability, customer trust, and strategic flexibility.
The visible cost is maintenance: more firefighting, more regressions, slower releases, and weaker confidence in delivery. Teams spend time reacting instead of improving. Product progress starts slowing down because more of the roadmap is displaced by operational work.
The less visible cost is often worse. Recurring reliability issues frustrate customers. Product teams become reluctant to commit to timelines. In that kind of codebase, AI coding tools can easily amplify the damage. They generate changes faster than the team can safely verify them, so one local fix can trigger a cascade of unintended side effects.
At that point, the damage is no longer just technical. It shows up as slower execution, lower confidence, and less room to grow. Most of that cost is measurable if you know where to look.
How to Spot Zombie Code
Zombie code is legacy code that’s technically alive, still running and still serving customers, but functionally dead: too fragile and too poorly understood to change safely. Not every messy system has reached that point. But some are already in the zone where routine maintenance is no longer enough.
Red Flags
Watch for these signs:
- Only a small number of people can safely change core parts of the system.
- Bug fixes and releases regularly trigger unrelated regressions.
- Maintenance and incident response are crowding out roadmap work.
- Customers are increasingly noticing reliability issues.
- Developers spend more time firefighting than building.
- Changes generated with AI regularly create side effects elsewhere in the system.
If several of these are true at the same time, you are no longer dealing with an ordinary mess. You are dealing with a system that needs focused intervention.
Quick Self-Assessment
Use these six yes/no questions as a rough diagnostic:
- Do critical changes depend on one or two people who “just know how it works”?
- Have recent bug fixes or releases caused unrelated issues?
- Is the team spending more time stabilizing than shipping meaningful improvements?
- Are reliability problems starting to affect customer trust or retention?
- Does the team avoid changing certain parts of the system because touching them risks breaking something else?
- Have internal cleanup efforts repeatedly started and stalled?
If you answer 0–2 yes, the system is under strain but still manageable. If you answer 3–4 yes, the risk is clearly rising and needs active intervention. If you answer 5–6 yes, the system is likely constraining the business and needs a structured rescue rather than more improvisation.
How to Rescue a Legacy System Without Stopping Revenue
The goal is not to make the whole system clean at once. The goal is to reduce business risk while restoring the team’s ability to change it safely.
Stabilize Revenue-Critical Flows First
Start with the parts of the system most directly tied to revenue, customer trust, and operational continuity.
Map the critical flows. Identify where failures have the highest business cost. Add monitoring where you currently have blind spots. Put safeguards around the highest-risk changes. Introduce targeted tests around the areas the business cannot afford to break. If rollback is hard, make rollback easier before you try to move faster.
This is also the point where your Definition of Done needs to tighten up. If the team keeps shipping changes that increase volatility, the rescue will fail before it starts. Stopping that pattern matters more at this stage than any improvement to code quality.
Replace the Worst Parts in Stages
Once the system is more stable, start reducing dependency on the worst parts instead of trying to rebuild everything.
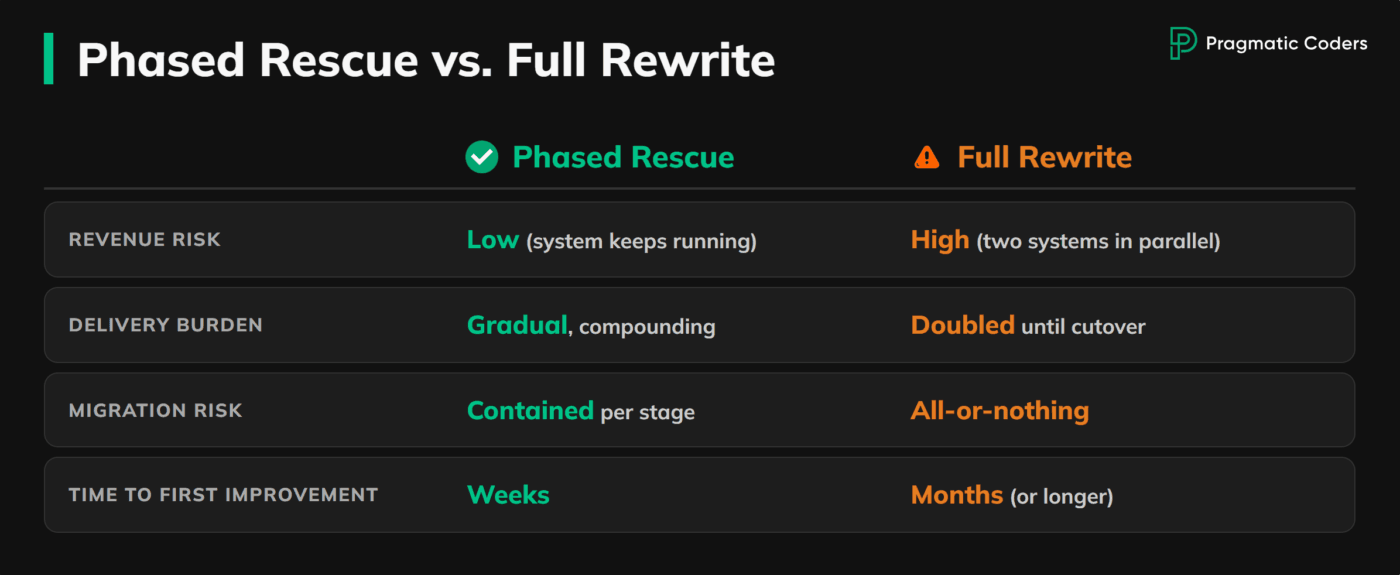
A phased modernization approach usually works better than a rewrite-first strategy. New components can be introduced around the most damaging parts of the system, with clear boundaries and measurable goals. That reduces migration risk and lets the business keep operating while engineering capacity begins to compound again.
The goal is not to make the architecture look cleaner on a diagram. It is to lower the blast radius of change, improve delivery confidence, and remove the parts of the system doing the most damage.
Avoid a Full Rewrite as the First Move
A full rewrite sounds attractive because it promises a clean reset. In practice, it usually creates a second system that has to be built while the first one is still carrying the business.
That doubles the delivery burden and usually drives costs up faster than teams expect. The old system still needs fixes, support, and operational attention, while the new one consumes the people most capable of understanding what the old one actually does. Teams also tend to underestimate migration risk. Business rules are often encoded in production behavior, ad hoc workarounds, and edge-case handling that nobody has fully documented.
A rewrite can make sense later. It is just rarely the safest first move when the business cannot afford disruption.
Use Big-Bang Replacement Rarely and Deliberately
There are cases where incremental modernization is not enough. Some parts of a system are too tightly coupled, too brittle, or too structurally broken to improve piece by piece.
When that happens, a controlled cutover can be justified. But it has to be treated as a managed transition, not a leap of faith. Validate in parallel where possible. Define rollback conditions in advance. Make the success criteria explicit. And be honest about what you are replacing, why it cannot be modernized incrementally, and what new risks the transition introduces.
Big-bang is not forbidden. It is just expensive enough that it should be chosen deliberately.
Measure Whether the Rescue Is Working
You do not need a vanity dashboard. You need evidence that the system is becoming safer to change.
Look at incident frequency, regression rate, lead time for meaningful changes, the share of engineering effort lost to maintenance, delivery predictability, and customer-facing reliability. If those indicators are not improving, you are probably moving effort around rather than fixing the underlying problem.
The rescue is working when change becomes less risky, the team regains confidence, and roadmap work stops losing every fight against operational chaos.
When Internal Recovery Stops Working
Some teams can stabilize and recover a system on their own. Some cannot.
The usual failure mode is not lack of effort. It is that the same team responsible for keeping the system alive is also trying to redesign it under pressure, while still responding to incidents, supporting releases, and answering the business for short-term outcomes. Cleanup work starts, stalls, and gets pushed aside the moment the next production problem appears.
That is when external help becomes a rational option. An independent project rescue effort can make sense when internal recovery keeps failing, ownership is too concentrated, or the business cannot afford another improvised cleanup push.
A proper rescue should begin with an audit of technical and operational risk, then move into stabilization, phased modernization, and knowledge transfer. The goal is to restore control.
What to Do if This Sounds Familiar
Your next move depends on how severe the situation is.
If you recognize only a few warning signs, tighten delivery discipline and protect the most critical flows before the system gets worse. If maintenance load and regressions are clearly rising, quantify the cost before the problem gets normalized. A practical next step is to review how to calculate the real cost of technical debt and turn vague frustration into measurable business impact.
If the system still generates revenue but feels increasingly unstable, run a broader diagnostic using 5 Red Flags: Diagnosing the Key Problems in IT Product Development. If the issue is no longer local but structural, it is worth examining what a proper project takeover or rescue actually requires before you commit to a larger modernization effort.
And if internal recovery keeps stalling, start with an independent assessment before making a bigger bet on a rewrite, a replatforming effort, or another internal cleanup plan.
Conclusion
Bad code becomes most dangerous when it is attached to a system the business cannot stop using.
That is why this problem is so often tolerated for too long. The system still generates revenue, so the pressure to change it never feels urgent enough — until reliability drops, delivery slows, and growth starts absorbing the damage.
The companies that handle this well are not the ones that wait for a perfect rewrite window. They are the ones that stabilize early, modernize deliberately, and reduce risk before the system starts dictating the business.




