Why Software Projects Fail and How to Fix Them

Software projects fail for predictable reasons. The problem is not bad luck. It is misalignment, unmanaged complexity, and weak feedback loops. If you learn to spot the signals early, you can stabilize delivery before delays and cost overruns harden into habits.
Many leaders underestimate the baseline risk. Large IT projects run 45% over budget and 7% over time while delivering 56% less value than planned. One in six IT projects becomes a black swan with average 200% cost overrun and schedule overruns of 70%. Organizations also lose significant budget to poor project performance, reported at around the low double digits.
Key Points
|
How to Measure Software Project Health
Failures persist because most teams try to manage symptoms and ignore causes. Delivery breaks when priorities conflict, complexity spreads, and nobody sees the full system. The solution is to watch patterns over time—not single misses—and act on them. When several signals trend the wrong way together, chances are the project is in bad health.
Start with a simple baseline. Look back over the last six to eight weeks. Compare today’s trend to the previous quarter. You are not looking for perfect numbers. You are looking for persistent movement in the wrong direction across a few dimensions at once.
Read signals in context. A mild slowdown after a major release may be normal. A sustained slowdown while rework and incidents rise is not. Normalize what you see by team size and stage. Early prototypes can look a bit messy. Mature products should show stable, repeatable flow.
Focus on correlation, not single metrics. Slower delivery that coincides with more production issues often points to quality debt and integration gaps. Costs rising faster than usage usually points to scope risk and architecture friction. When multiple trends turn at once, assume a system problem and look for a recent change in scope, structure, or staffing.
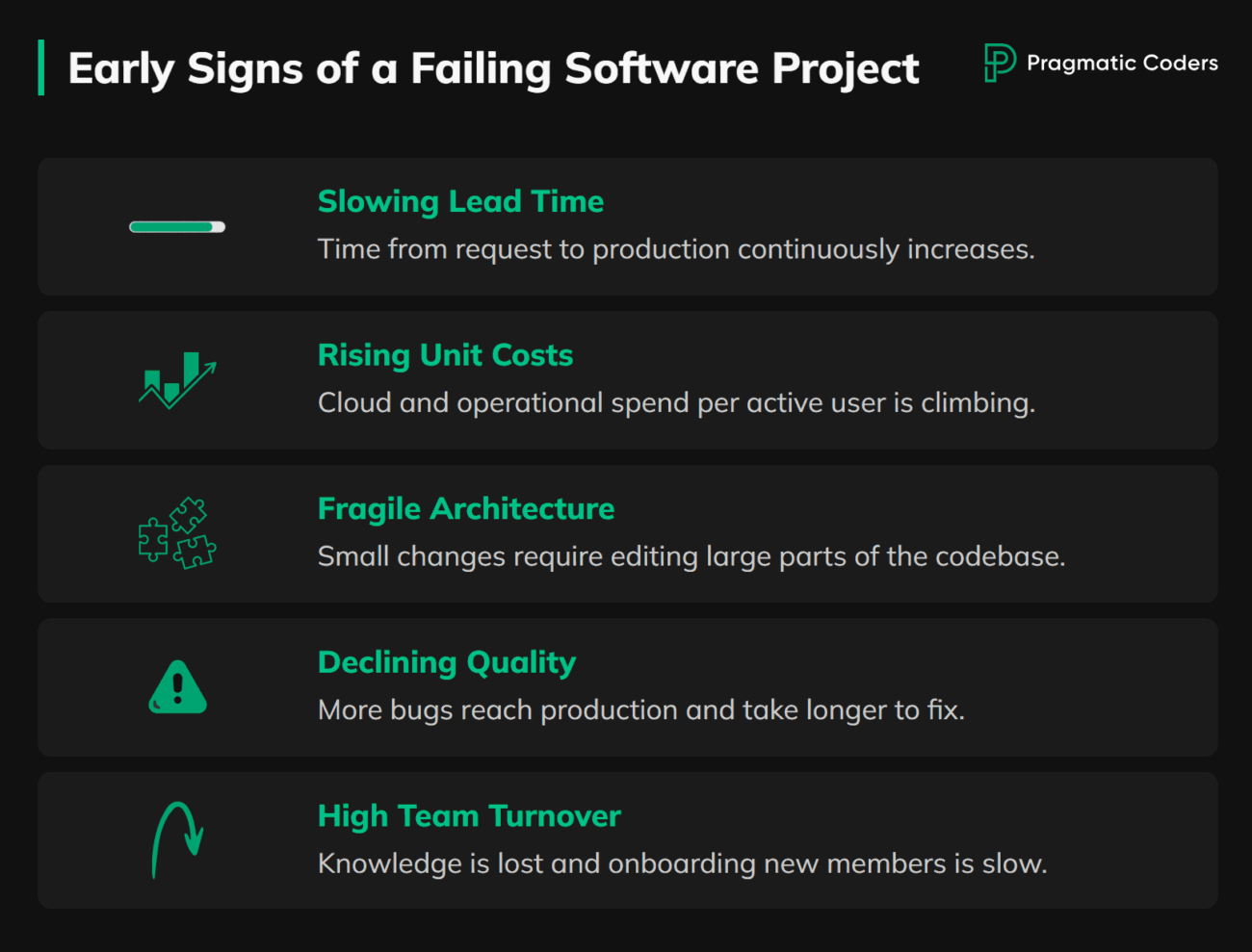
How To Spot Early Warning Signs Your Software Project Is Failing
One miss is normal. A pattern of misses means the system is off. Treat these as smoke alarms for delivery risk.
Lead Time Keeps Getting Longer
Watch request‑to‑production lead time alongside in‑flight work and throughput. If lead time stretches while WIP climbs and throughput falls, hidden queues and context switching are slowing you down. The most common causes include:
- Too much work‑in‑progress creates queues and context switching
- Fuzzy priorities and scope churn restart partially done work
- Handoff bottlenecks introduce wait states and approvals
- Slow integration and testing delay feedback and fixes
Compare Run Costs To Active Usage
Track monthly cloud/ops spend per active user. When spend outpaces value and cost‑per‑user drifts up, the economics are off. Typical reasons are:
- Over‑provisioned infrastructure and idle capacity
- Inefficient cloud usage (no reservations/savings plans, high egress)
- Over‑engineered architecture with high operational overhead
Small Changes Touch Too Much Code
Track files or services touched per change and deployment stability. If trivial features force many cross‑repo edits, rollbacks are frequent, and deploys feel risky, architecture is adding friction. This usually happens because:
- Tight coupling and microservice sprawl
- Unclear module/service boundaries and ownership
- Thin automated tests reduce refactor confidence
- Immature, or lack of, CI/CD
More Production Bugs And Slower Recovery
Monitor defect escapes, incident frequency, and mean time to restore (MTTR). If more defects reach production, similar incidents repeat, and MTTR trends upward, quality debt is compounding. Frequent contributors include:
- Insufficient automated testing
- Weak observability and incomplete runbooks
- Lack of refined acceptance criteria
High Team Churn And Opaque Updates
Track turnover, time‑to‑first meaningful PR for new joiners, onboarding speed, and the clarity of status reports. Frequent team changes, slow onboarding, and updates without explicit risks, decisions, or delivered outcomes are red flags. Likely causes:
- Weak knowledge transfer and thin documentation
- Key‑person dependency
- Misaligned incentives (rewarding output over outcomes)
- Poor vendor governance (no open risk log, vague demos)
Before you act, run a quick health check to baseline risk and prioritize.
Quick Software Project Health Check
Use this short assessment to quantify risk and prioritize actions. Answer questions across governance and communication, delivery performance and metrics, team and resource management, quality and technical practices, and scope and risk management. If you want to go one level deeper and validate what status reports may be hiding, these 15 questions to audit your IT project status will help you verify progress directly in your systems, codebase, and delivery process.
You’ll receive an overall risk level, a project health score, and a count of critical and high risk indicators.
Free Software Project Health Assessment
Is your software project silently failing? Answer a quick 2-minute questionnaire to receive an immediate health score and understand specific risk areas in your project.
How To Fix A Failing Software Project: A 5-Step Playbook
Contain risk first. Then improve delivery incrementally.
- Regain Control Of Scope And Priorities. Freeze non-essential scope and cut to a minimal, outcome-focused backlog. Clarify acceptance criteria for every item. When you cut scope, it helps to see what still matters for product health, not only what is urgent today. The Product Health Checklist can support that reset.
- Create Immediate Visibility. Stand up a simple delivery dashboard for lead time, throughput, work-in-progress, defects, and incidents. Run a weekly operating review with decisions, risks, and owners recorded. Dashboards help, but teams still miss how risk feels day to day. If every week is reactive, read Is your project on fire? Self-diagnosis for a clear symptom list.
- Stabilize Architecture And Quality. Identify high blast radius hotspots and simplify interfaces. Add tests where coverage is weakest, fix flaky CI, and automate deploys to staging. Target smaller batch sizes, faster safe deploys, and fewer regressions.
- Reset The Plan With Realistic Capacity. Re-estimate using historical throughput and include buffers. Renegotiate dates by trading scope and time, not quality. Target predictable sprints aligned to real capacity.
- Fix Communication And Decision Rights. Define who decides what across roadmap, architecture, releases, and incidents. Replace status meetings with demo-and-decide reviews. Target faster decisions and fewer priority conflicts. When delivery starts to slip, this also means being explicit about how and when risks and delays are raised with executives. If you are unsure how to surface problems early without losing credibility, this framework on how to talk to executives about project delays explains how to frame facts, risks, and trade-offs so leaders can make decisions.
Note on feasibility: Not every project can be stabilized this way. In-house teams can usually implement these changes directly. With external vendors, success depends on genuine cooperation and transparency. If a vendor resists scope control, visibility, or architectural simplification, treat it as a blocker and escalate. That’s often the point to consider a transition plan or bringing in outside help.
![Is your project on fire [EBOOK]](https://www.pragmaticcoders.com/wp-content/uploads/2026/02/Is-your-project-on-fire-EBOOK.png)

When To Bring In External Help For A Failing Project
Bring in experienced help when risk compounds faster than you can respond. Signals include repeated milestone misses, architectural gridlock, incident fatigue, and loss of stakeholder trust. An effective partner will expose risks quickly, realign the backlog to outcomes, simplify architecture, and create the visibility you need to make decisions.
If you need a structured way to stabilize delivery, consider a focused engagement like our software project rescue services. It is designed to surface the biggest risks first and get you back to predictable delivery.
Conclusion
Failure is not random. It follows patterns that you can see early in your flow metrics, quality signals, costs, and team behavior. Diagnose root causes rather than chasing symptoms. Stabilize scope, visibility, and architecture, then reset plans to match real capacity. Use the assessment to pinpoint where to start, and take one stabilization step this week. In two weeks, review the data and adjust. That cadence is how projects recover and stay healthy.




