IT Project Audit – When Your Project Is on Fire and How to Save It

The goal of this article is to show you how to stop ignoring the smoke and how to conduct a reliable self-diagnosis of your project. I will explain why an independent technology audit is not a “raid” on the team, but the first step to regaining control, predictability, and real business value. In IT, as in medicine, early detection of pathology allows for effective treatment, while delay leads to costly and painful amputation of entire modules, budgets, and sometimes trust in technology itself.
The “Watermelon Project” Phenomenon
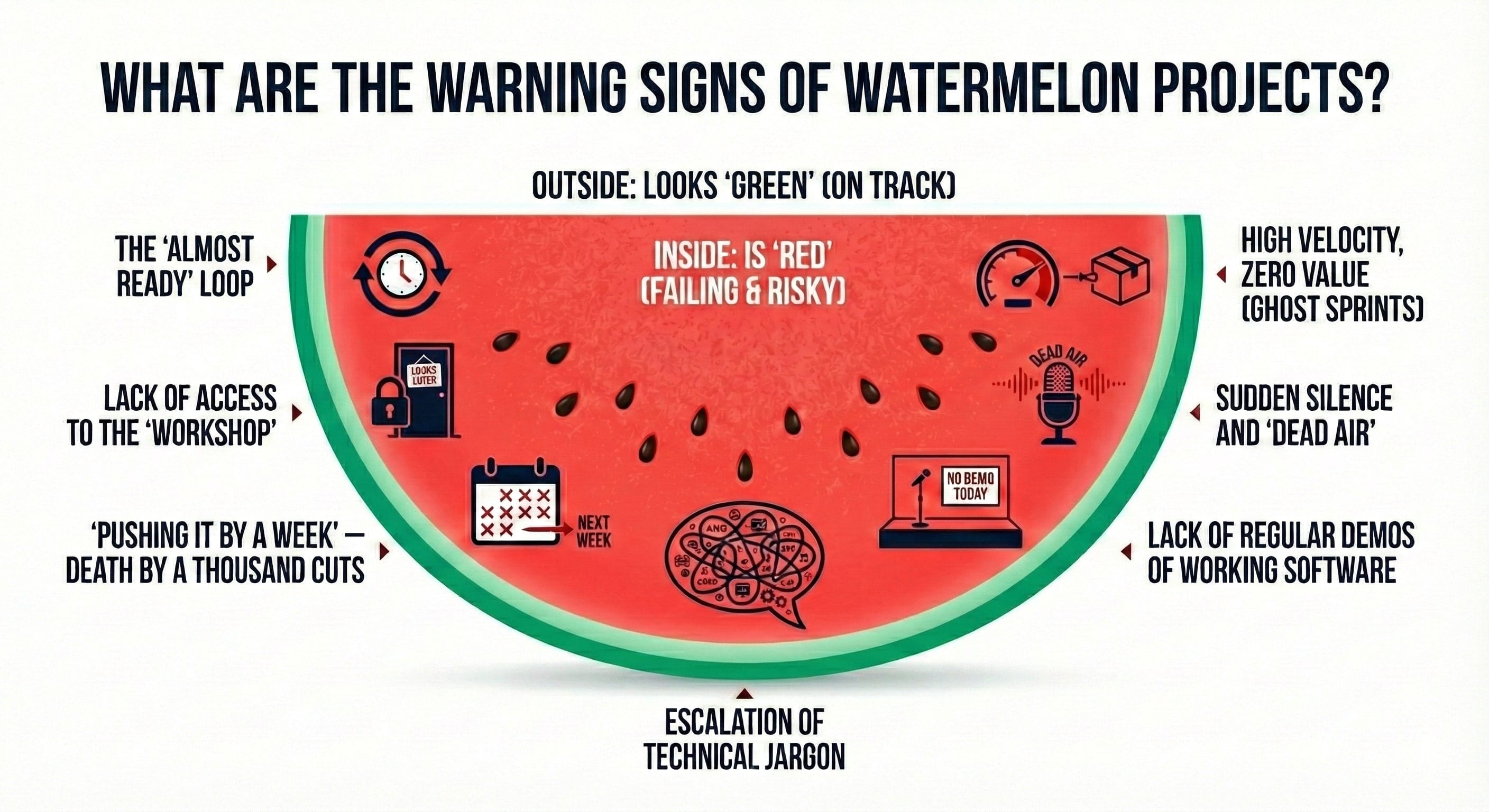
Have you ever sat in a status meeting, looking at beautifully prepared PowerPoint slides, seeing nothing but green tiles in Jira, yet felt a growing sense of unease in your gut? It’s that specific kind of intuition that tells you that although everything looks perfect on the surface, something is going very wrong underneath. In the IT world, we call this the “Watermelon Project” phenomenon – green on the outside, alarmingly red on the inside.
A Watermelon Project is one of the most dangerous scenarios in the technology business. Sponsors and stakeholders are fed positive reports, the development team ensures that “everything is under control,” and the deadlines… well, the deadlines are “dynamic.” The real problem arises at the moment of truth. This was the case for one of our clients – a bank from the UK. A consulting firm from the so-called Big Four had been reporting progress for nearly two years, charging substantial fees. However, when it came time to show a working product, it turned out that the application physically did not exist. The code we analyzed as part of the project rescue contained hundreds of empty methods with comments like: “logic will need to be implemented here.” It was a pure facade, painting the grass green for millions of pounds.
Why am I writing about this? Because most “fires” in IT projects don’t start with a sudden explosion. It’s a slow smoldering process that is often ignored – sometimes out of ignorance, sometimes out of hope that “it will work out somehow,” and sometimes because of an organizational culture where no one wants to be the messenger bringing bad news. When that uneasy feeling appears, the worst thing you can do is ignore it. The right move is to replace intuition with structured verification. A practical way to start is by asking the right diagnostic questions that expose gaps between reported progress and actual delivery.
You can turn a bad gut feeling into facts. This article gives you a full map. If you want a short written self-check first, use Is your project on fire? Self-diagnosis. It will not replace an audit, but it helps you sort symptoms fast.
![Is your project on fire [EBOOK]](https://www.pragmaticcoders.com/wp-content/uploads/2026/02/Is-your-project-on-fire-EBOOK.png)
Four Levels of Fire: How to Recognize That Something Is Wrong?

Diagnosing a burning project requires looking at the organization from multiple perspectives. Based on 15 years of experience at Pragmatic Coders in rescuing products that “couldn’t fail,” we have developed a model of four levels of warning signals. Each of them, if occurring independently, is a cause for concern. If you see two or more – your project is likely already on fire.
1. Product and Business: A Feature Factory Without a Compass
The most common warning signal at the business level is a lack of a coherent vision. If you ask five people in the team: “Why are we building this product?”, and you get five different (or worse – evasive) answers, you have a problem.
Many companies fall into the trap of being a “feature factory.” The roadmap becomes a random wish list of individual stakeholders rather than a thought-out strategy for delivering value. In such an environment, priorities change every week, and the team jumps from task to task without finishing any of them. The result? Regular releases that don’t bring any change to key business metrics.
It is worth distinguishing two key metrics here: Output (the amount of work delivered, e.g., the number of tasks in Jira) and Outcome (real business change, e.g., an increase in conversion). If your reports only focus on the former, and no one measures the real impact of delivered features on the business, you are likely burning your budget on things no one needs.
2. Process (Delivery): Massive Multitasking and a Lack of Closures
How can you tell if the delivery process is inefficient? Look at the Cumulative Flow Diagram. If the number of tasks marked as “In Progress” is constantly growing and rarely moves to “Done,” your team is stuck in a multitasking loop.
One of the most common “silent killers” is a lack of a clear Definition of Done (DoD) and gaps in task preparation (Definition of Ready – DoR). When tasks are not well-defined before they start, developers have to “guess,” leading to errors, rework, and frustration. On the other hand, the lack of a reliable DoD means that tasks considered finished come back with regression errors, breaking what supposedly worked before.
Another signal is growing Lead Time – the time from idea to deployment. If, with each passing month, delivering the simplest change takes more time and costs more emotion, it’s a signal that the process doesn’t work, and bottlenecks (e.g., one person holding 90% of the system knowledge) are paralyzing development.
3. Technology: The Seismic Effects of Technical Debt
Technology is the place where a lie is hardest to hide because “the code tells the truth.” A technical self-diagnosis is based on several hard questions:
- Does every task meet the Definition of Ready? If developers start writing code without a full understanding of the requirements, they are building sandcastles.
- Are there automated tests? A system without such tests is by definition a legacy system – every change is fraught with gigantic risk.
- Are deployments to production “big events”? If your team plans a release for 3 AM on a Sunday because “it’s safest then,” it means you don’t trust your own software.
- Does fixing a bug include a Root Cause Analysis (RCA)? Just saying “we fixed it” is not enough. If the bug returns, it means the process is generating bugs, and you are only patching the symptoms.
Technical debt works like a bank loan – you can take it to speed up, but the interest will eventually consume you. If every small change causes an avalanche of errors in other parts of the system, your interest has become higher than your capital.
4. People: Turnover, Cynicism, and Hero Culture
People are the most sensitive barometer of a project’s state. High turnover, especially the departure of key individuals (so-called “Rockstars”), is a clear signal of fire. Frustration from working in chaos quickly turns into apathy and cynicism.
Another dangerous phenomenon is the so-called “hero culture.” This is a situation where there is only one person in the team (often the CTO or lead architect) who is able to fix a critical error in the middle of the night. On one hand, the company rewards them, but on the other – they become a gigantic business risk. What happens if they get sick or, even worse, get a better offer from a competitor? Then your project hits a “Bus Factor = 1” and grinds to a halt.
Our four levels cover product, delivery, tech, and people. For a practical scan of product health—strategy, discovery, delivery, and leadership—add the Product Health Checklist. It pairs with the Product and Process parts of the model.

The Anatomy of a Technology Audit: More Than Just a Code Review
Most people, when hearing the word “IT audit,” imagine a dragon-developer entering a cave, looking through source files, and stating with disgust that everything should be thrown away. Such an approach is not only wrong but also useless for the business. A reliable technology audit, like the one we conduct at Pragmatic Coders, is a multidimensional process designed to provide answers about business risks, not just code aesthetics.
Conversations That Say More Than the Code
We start the audit not from the IDE, but from conversations. Code is only the implementation of ideas (or the lack thereof). To understand why a project is on fire, we need to talk to three groups:
- With the Client and Business: We ask what the goal of the product is and what the biggest concerns are. It often turns out that the business wants speed, while the developers are building an “architectural monument” that effectively kills that speed.
- With the Development Team: Developers usually know exactly where the problems are. If we create a safe environment for them to have an honest talk, they will point us to the “darkest corners” of the system in 15 minutes. This is where we apply the previously mentioned RCA – we look for the sources of errors, not someone to blame.
- With Users: This is the final instance. If the system is “technically perfect,” but an internal user says that “it’s scary to click because everything churns for half a minute,” then the technical audit must find the cause of those delays (e.g., a lack of observability or an overloaded database).
The Result of the Audit: A Takeover and Debt Repayment Plan
An audit cannot end with just a report listing errors. Its result must be a concrete Takeover Plan. This is a document that says: “We know what is broken, we know why it happened, and we have a plan for how to fix it without interrupting the delivery of new business value.”
For us, an audit is a planning tool. It allows us to determine the competencies of the team needed for the rescue (do we need an architect, UX specialists, or someone to “clean up” the cloud infrastructure?) and set a real timeline for repaying critical debt.
Rescue Plan: First Steps After the Fire
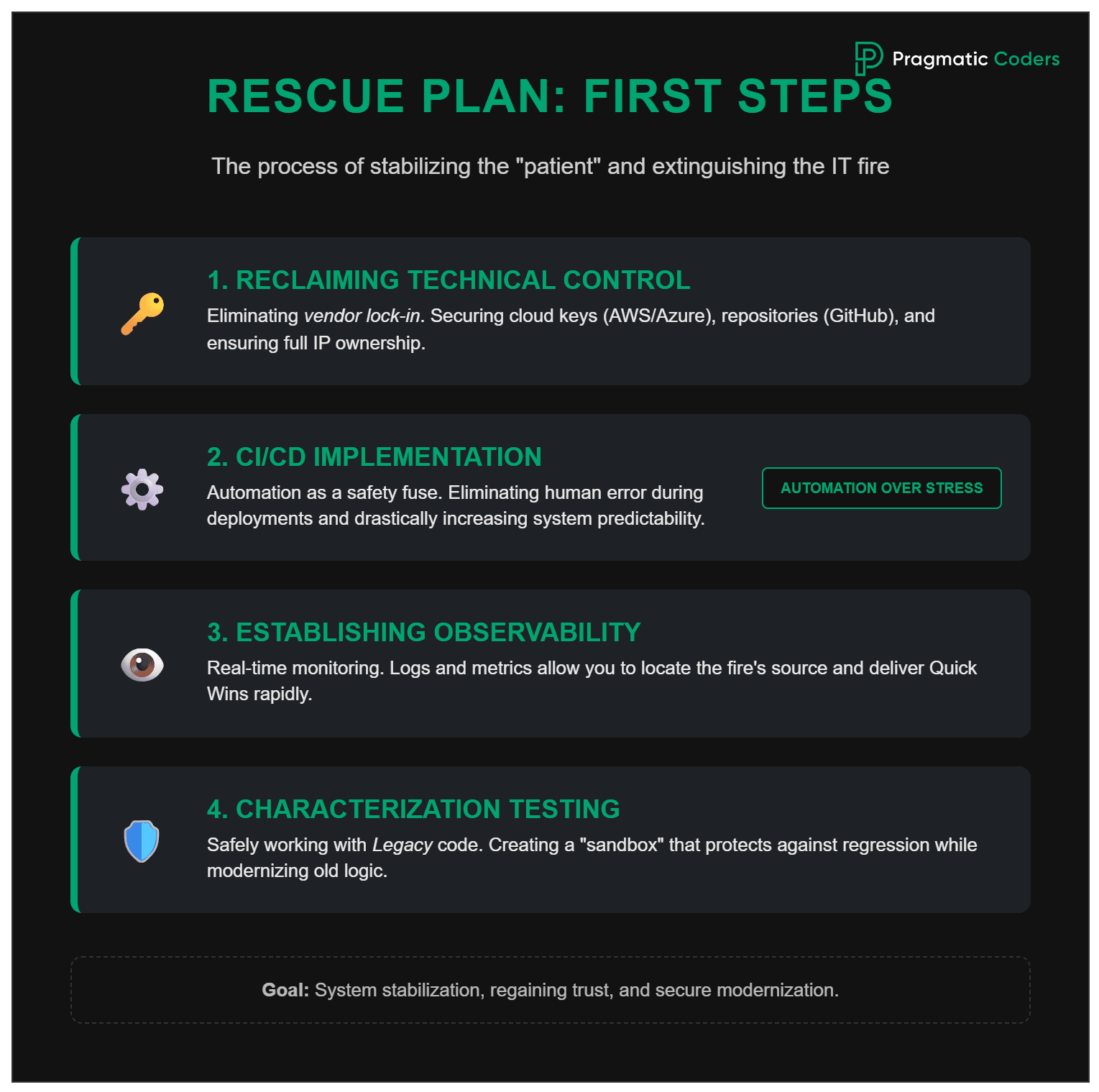
Once the diagnosis is made, it’s time for surgery. Rescuing an IT project is not a sprint – it’s a process of stabilizing the patient. Here are the four pillars we start every rescue project with:
1. Regaining Technical Control (Access & IP)
It may sound unbelievable, but in projects “on the brink of the abyss,” it’s very common for the client not to have full access to their own intellectual property. Server passwords are “somewhere with a developer,” documentation in Notion is out of date, and access to the code repository is limited.
The first rescue step is to regain full control:
- Gathering all keys to the clouds (AWS, Azure), repositories (GitHub, GitLab), and payment gateways.
- Confirming that the client is the legal and technical owner of the code and data.
- Locating documentation (even if it’s rudimentary).
This eliminates the phenomenon of so-called vendor lock-in, where the current provider holds the client “hostage” to the technology.
2. CI/CD Implementation – Automation as a Safety Fuse
A lack of automation is the shortest path to disaster. Continuous Integration and Continuous Deployment (CI/CD) are processes in which every change in the code is automatically tested and (if tests pass) prepared for deployment.
Why is this crucial for rescuing a project? Because it eliminates human error. If the deployment to production is performed by an “automaton” rather than a tired programmer at 3 AM, the predictability of the system increases drastically. For the business, CI/CD means that every bug fix can reach users the same day, rather than once a month.
3. Ensuring Observability
Many projects are on fire because no one knows what is happening inside the application. Observability is the collection of logs, metrics, and traces that allow you to see the system in real time.
Without monitoring, developers are like firefighters working in thick smoke – they know it’s hot, but they can’t see the source of the fire. When we introduce observability, it suddenly turns out that 80% of the errors are generated by one poorly written module that can be fixed in one day. This yields immediate victories (quick wins) that rebuild team morale and client trust.
4. Characterization Testing: Safe Work with Legacy
When taking over a “messy” project, we must be sure that by fixing one thing, we are not breaking ten others. We use the method of characterization testing here. It involves writing tests that record the current (even incorrect!) behavior of the system.
In this way, we create a “safe sandbox.” We can refactor old code knowing that if we change anything in the logic, the tests will notify us immediately. It’s the only way to safely modernize systems that no one fully understands anymore.
Why Do We Wait So Long? Psychological and Cultural Barriers
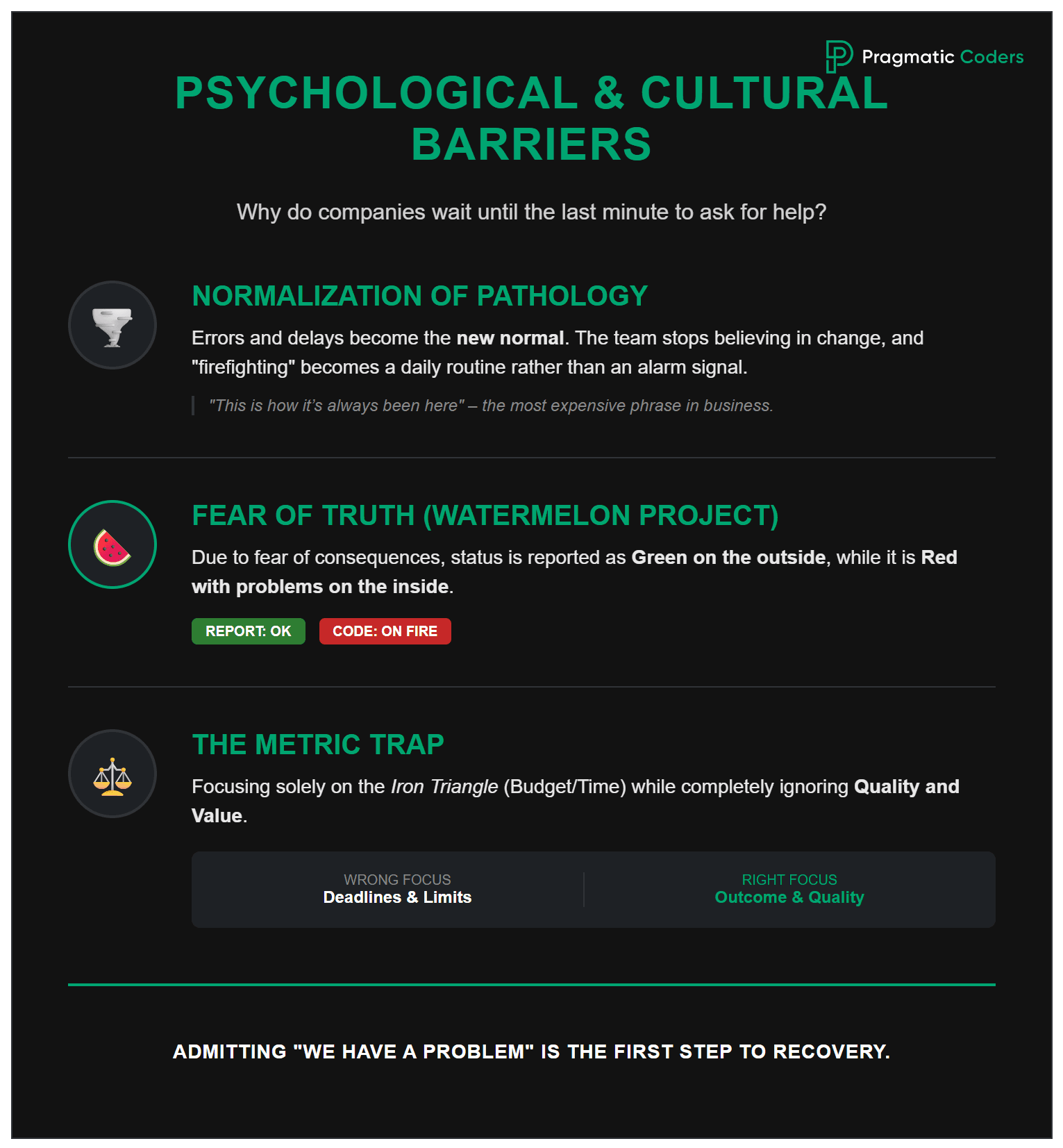
Given that fire signals are often so clear, why do many companies wait until the last minute before asking for help? The answer is rarely technical. It most often lies in psychology and organizational culture.
Normalization of Pathology
“It’s always been this way for us” – this is one of the most dangerous sentences in business. When production bugs become a daily occurrence and delays become the norm, the team stops seeing them as a problem. This is a normalization of pathology. People stop believing it can be different, and “firefighting” becomes their main source of professional identity.
Another aspect of the normalization of pathology is the lack of control and low transparency. This often stems from the fact that managers learned to manage in corporate environments where budgets are large enough that inefficiency is tolerated for years. In smaller, dynamic organizations, such tolerance is a death sentence for the product.
Fear of Bad News
In many organizations, there is a culture of punishment for mistakes. If a PM or Tech Lead is afraid that admitting a delay will end in a “talking to” by the board, they will do everything to hide the problem. This is exactly when “Watermelon Projects” are born. Transparency dies under the pressure of fear for one’s own career.
A reliable audit and a healthy approach to building software require the courage to say: “We have a problem, we don’t know how to solve it yet, but we have to stop to avoid running off a cliff.”
Measuring the Wrong Things
Business often focuses on budget and time (the so-called iron triangle), ignoring quality and value. This is a mistake. Budget and time are important, but if you deliver “something” on time and within budget, but that “something” is buggy and useless to the client, you have effectively lost 100% of the invested funds.
A properly implemented process (e.g., Scrum used according to the rules, not a “broken” version tailored to the company structure) forces transparency. Sprint Goals, metrics such as Throughput or Velocity, allow you to notice drops in team performance much earlier than an upset client will.
Summary: From Chaos to Predictability

A fire in an IT project is not a death sentence, provided you react early enough. Ignoring the smoke only raises the costs of a future rescue operation. So, how do you start?
- Do a self-diagnosis: Use our four levels of warning signals (Product, Process, Technology, People). Be brutally honest.
- Bet on transparency: Stop measuring the “number of tasks” and start measuring the real value delivered to users (Outcome).
- Don’t be afraid of an audit: An independent look from the outside will allow you to see what your team has already become accustomed to. An audit is not a verdict; it’s the foundation of a new strategy.
- Stop the death loop: If lead time is growing and quality is falling – don’t hire more people. Fix the process, introduce CI/CD, and pay off technical debt.
Rescuing software is an investment in the foundations of your business. The goal is not to “rewrite everything from scratch” (which is rarely good advice unless the code consists of empty methods like in the UK bank mentioned), but to restore the system’s ability to evolve. When the team stops being afraid of its own code, and the client regains confidence in deadlines, the project stops burning and starts building a real market advantage.
If you feel that your project is starting to look like a watermelon – don’t wait for the red to spill out. A technology audit is the first step to peaceful sleep and a predictable business.





