Machine learning for fraud detection in fintech

A new study by Juniper Research has found that merchants will lose over $206 billion to online payment fraud between 2021 and 2025.
This is almost 10 times the net income of Amazon in 2020.
It’s more than clear fintech founders need to take steps to detect fraud and combat it. One of them can be using machine learning (ML).
With AI algorithms trained on large datasets of historical transactions and other data points, identifying patterns and anomalies indicative of fraudulent activity seems simpler than ever before.
But is it really?
In this article, we’ll discuss the application of machine learning software for fraud detection solutions – its benefits, challenges, and use cases.
Traditional methods of fraud detection
Let’s start by explaining how banks and other financial institutions have used to approach detecting fraud so far.
Fraud detection is an array of techniques for detecting unauthorized transactions, identifying fraudulent loan applications, preventing money laundering, and combating identity theft.
Traditional fraud detection methods rely on human expertise and manual processes to identify and prevent fraud. These methods include:
- Rule-based systems: Rule-based systems are computer programs programmed with a set of rules to identify any untypical behavior of a user. These rules are typically based on historical data and expert knowledge. Here are a few examples of such rules. A transaction might be flagged as fraudulent if…
- …there is a sudden increase in the number of transactions from an account.
- …it is made from a location that is inconsistent with the customer’s usual location.
- …it is made from a device that is not typically used by the customer.
- …it is sent to a beneficiary that is not typically used by the customer.
- Statistical analysis: Statistical analysis is used to identify patterns and anomalies in data that may indicate fraudulent activity. This can involve techniques such as outlier detection (identifying data points significantly different from the rest of the data) and clustering (grouping data points together based on their similarity).
- Human review: Manually reviewing transactions or activities for signs of fraud.
Traditional methods of fraud detection have their advantages. For example, they are relatively inexpensive to implement and can be used to detect a wide range of fraud schemes.
Yet they also come with some drawbacks. They can be easily circumvented by fraudsters who know the rules and are constantly working on smarter ways to commit crimes.
Additionally, statistical data analysis and human review can be time-consuming and error-prone.
As you can see from the statistics I drew at the beginning of the article, fraud is a growing problem where traditional methods won’t be enough. So what can fintechs do then? The answer is: apply data science and machine learning.
What is machine learning?
Machine learning (ML) is a type of artificial intelligence (AI) that allows software applications to become more accurate in predicting outcomes without being explicitly programmed to do so. Machine learning algorithms use historical data as input to predict new output values.
ML algorithms can be broadly divided into supervised learning and unsupervised learning.
- Supervised learning: In supervised learning, the machine learning algorithm is trained on a dataset of labeled examples. These examples include both the input data and the desired output value. The algorithm learns to predict the output value for new input data by finding patterns in the training data.
- Unsupervised learning: In unsupervised learning, the ML algorithm is trained on a dataset of unlabeled examples. These examples include only the input data without the desired output value. The algorithm learns to find patterns in the data without prior knowledge of the output values.
ML algorithms are used in a wide variety of applications:
- Fraud detection: Detecting fraudulent transactions and other types of fraudulent activity.
- Recommendation systems: Recommending products, movies, and other content to users based on their past behavior. Many big companies like Netflix or Amazon use ML to keep you on their platform longer. The better recommendation they give you, the bigger the chances you’ll watch the next season of The Witcher (I don’t believe there’s any algorithm that would make you do so, but still) or buy another product. These systems find use in much more serious fields as well, like asset management.
- Image recognition: Identifying objects and faces in images. For example, machine learning is used in CAPTCHAs – security mechanisms that ask you to select all bikes in an image to ensure you’re a human, not a bot.
- Natural language processing: Generating human language.
- Medical diagnosis: Diagnosing diseases and other medical conditions.
As you can see, machine learning can be applied to solve various problems.
However, it is essential to note that ML algorithms are only as good as the data they are trained on. The ML algorithm will learn to make biased or inaccurate predictions if the training data is biased or inaccurate.
Additionally, it’s important to note that it can be challenging to understand why an ML algorithm is making a particular prediction.
So what is actually the underlying process behind machine learning?
How do machine learning systems work?
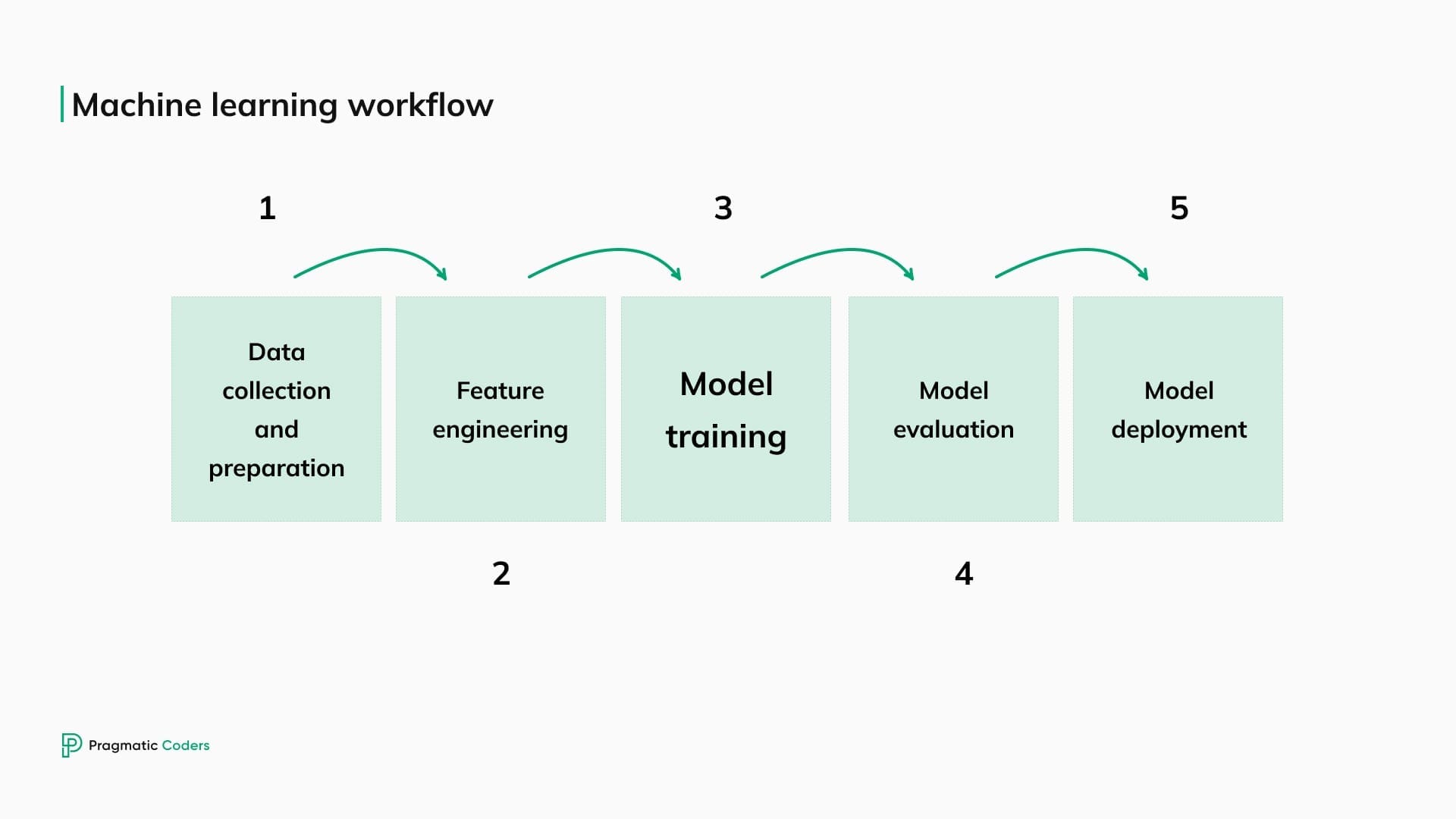
Let’s go through a supervised machine-learning workflow for a financial product. It typically involves the following steps:
1. Data collection and preparation
The first step is to collect historical data on both fraudulent and legitimate transactions. This data may include transaction amount, date, time, location, device type, and customer information. Once the data is collected, it must be cleaned and preprocessed to remove any errors or inconsistencies.
2. Feature engineering
The next step is to identify and extract relevant features from the data. These features will be used by the machine learning algorithm to learn to identify fraudulent transactions. Some standard features of the fraud detection algorithm include:
- Transaction amount
- Date and time of transaction
- Location of transaction
- Device type used for transaction
- Customer information (such as name, address, and IP address)
- Past transaction history
3. Model training
Once the features have been extracted, the next step is to train a machine-learning model. Many machine learning algorithms, such as decision trees, random forests, and support vector machines, can be used for fraud detection. The algorithm best suited for the specific fraud detection problem will depend on the nature of the data and the particular fraud types being targeted.
Then, the actual training begins. The algorithm is given a set of labeled data, where each data point is marked as either fraudulent or legitimate. The algorithm then learns to identify patterns in the data associated with fraud.
4. Model evaluation
Once the model has been trained, it must be evaluated on a held-out test set. This will indicate how well the model will perform on new data. If the model is not performing well enough, it may need to be retrained with more data or different features.
5. Model deployment
Once the model is evaluated and performing well, it can be deployed to production. This means the model will be used to score new transactions and identify any likely fraud.
Traditional methods of fraud detection vs. machine learning
How do the two methods compare to each other?
As you can see, machine learning and traditional fraud detection methods are two different leagues. ML models update in real time, allowing for immediate responses to suspicious activities. Finally, they lower operational costs, reducing the need for manual review so that teams can focus on strategic tasks.
Case studies of ML for fraud detection in fintech
Machine learning is used in a variety of ways. This type of artificial intelligence can work great for credit card fraud detection, spotting suspicious insurance claims, or insider trading.
That’s for the theory. How do companies put it into practice?
Here are a few examples of how financial organizations use these machine-learning techniques to detect fraud.
Coinbase: Harnessing machine learning to spot user ID fraud
Unlike in-person ID authentication, where holograms and special lighting can be used, the online environment poses challenges. To overcome this, Coinbase, a popular cryptocurrency exchange platform, uses machine-learning algorithms for image analysis.
For instance, they use a face-similarity algorithm that automatically extracts and compares faces from uploaded IDs, revealing scammers who reuse the same photo for multiple accounts. This approach allows Coinbase to quickly identify and address fraudulent activities.
Capital One: Machine learning for credit card fraud detection
Capital One is a major American bank specializing in credit cards, auto loans, and banking services. With fraud being a constantly growing problem, and the US being the most credit card fraud-prone country in the world, no wonder Capital Once decided to go for ML to fight it.
Capital One employs machine learning to detect credit card fraud by training advanced ML models on a comprehensive dataset. These sets include various types of information, from transaction and cardholder to geospatial and temporal data. What’s more, they contain contextual information like work hours and spending habits, to identify unusual transactions. Thanks to that, fraud detection is way more effective and precise.
In addition, they utilize a framework of six essential questions (“what, who, when, where, why, and what if”) to uncover patterns and anomalies in fraudulent activities.
PayPal: Using ML for signup, login, and payment frauds
Signup fraud
Signup fraud, one of the fastest-growing types of deception, involves scammers using stolen or fake identities to open financial accounts. Detecting it is challenging because it’s the first interaction with the customer.
To combat this, PayPal employs algorithms that analyze various data sources like device information, third-party checks, identity scores, session analysis, and enrollment data to identify anomalies, such as user location inconsistencies or difficulty entering basic information.
Login fraud
Login fraud, a rapidly growing problem, involves unauthorized access to customer accounts through stolen credentials.
PayPal uses real-time machine learning models to identify legitimate customers, analyzing device info, email, IP, phone, transactions, and behavior to detect high-risk activity like multiple login attempts or unusual account changes.
Payment fraud detection systems
Payment fraud uses stolen card details without the cardholder’s knowledge. To detect this, PayPal relies on previous transaction data and analyzes device, email, IP, phone, user, and address information. Signs of fraud include address mismatches, unusually large orders, and multiple card use for shipments to the same address, with these signals indicating a higher likelihood of fraud.
Fraud detection in digital onboarding
Detecting fraud is essential in digital onboarding, especially in the financial services industry, when customers share the most private data.
With the rise of online transactions, there has also been an increase in sophisticated fraud attempts. To combat this, digital onboarding processes incorporate various tools to authenticate user identities, recognize suspicious patterns, and flag potential fraudulent activities in real-time.
Some key methods for fraud detection are:
- Verifying identities through document scans and facial recognition.
- Using device fingerprinting to identify suspicious login attempts.
- Analyzing user patterns with behavioral biometrics .
- Employing AI-driven risk scoring to gauge the likelihood of fraud
While these technologies improve security ,the real challenge is to implement them without introducing unnecessary hurdles for legitimate users.
Learn more: How to design digital onboarding to retain users: App founder’s guide
Challenges of using ML for fraud detection in fintech

There’s always a catch, right?
Despite its benefits, creating a fraud detection system that incorporates a machine learning system goes with some challenges.
- Data quality: Poor data quality costs businesses an average of $3.1 trillion per year, according to IBM. ML algorithms are only as good as the data they are trained on. Fintech companies need to ensure that they have access to high-quality data in order to develop effective fraud detection models.
- Model explainability: Explaining how machine learning models, especially complex ones like deep neural networks, make decisions can be tricky. This makes it hard for companies to figure out why their models are marking some transactions as suspicious.
- Regulatory compliance: Financial companies need to comply with a variety of regulations, such as the General Data Protection Regulation (GDPR) in the European Union. These regulations can impact how finance companies can collect, use, and store data, which can make it more difficult to develop and deploy ML fraud detection systems. Recently, Regulatory Technologies (RegTech) have proven to be of great help in achieving compliance.
- Ethical considerations: The way the algorithms work can spark controversies. You might have heard about the Dutch scandal, where a machine learning system that was used to detect childcare benefit fraud wrongly accused more than 20,000 families of fraud.
The future of machine learning for fraud detection systems
According to a research report by Markets and Markets, the global fraud detection and prevention (FDP) market is expected to grow from $27.7 billion in 2023 to $66.6 billion by 2028.
This growth is fueled by several factors:
- the increasing use of digital technologies and the Internet of Things,
- the rising cost of fraud, and
- the growing adoption of fraud analytics and risk-based authentication solutions.
These trends show a high demand for FDP (fraud detection and prevention) generation fraud management solutions already, which will only increase in the coming years.
It’s worth implementing them right now.




