Using AI in Software Development: Strategies to Stay Ahead

AI isn’t just another item on the roadmap. It is the roadmap. From UI mocks to data pipelines, entire workflows can now be delegated to AI Agents and services. What used to take months now (potentially) takes a week.
But speed comes with a cost. Once you move from MVP to production, things get real. Prompts fail. Costs spike. Shortcuts collapse. What worked in a demo starts falling apart under load.
This guide is about using AI to build things that hold up—at scale, in the wild. You’ll learn how to pick the right models, engineer prompts with precision, and bake in the reliability, testing, and cost controls that real systems need.
If you’re ready to move beyond demo-ware and ship AI-built software that lasts, you’re in the right place.
Key Points
|

Technical Integration: From Building Blocks to Production
Modern MVP development is faster than ever, thanks to the growing ecosystem of AI tools. Let’s take Miro AI, for example. The built-in AI features let you generate user stories or app prototypes, or even simulate UX research. You don’t have to build everything yourself anymore. You can delegate entire features to specialized AI solutions or agents, and focus on stitching them together.
- Need screens and UIs? Let Figma Make generate your UI from prompts. Alternatively, here’s our guide on how to create UI prototypes with Claude and ChatGPT.
- Need UX writing? There are dozens of solid AI writing tools that handle tone and structure.
- Need to crunch data? Tools like PandasAI and AutoML platforms help you analyze or model datasets without writing complex pipelines.
The real value today isn’t just using AI—it’s knowing which tools to pick and how to combine them. What used to take months to build can now be prototyped in a few days. That’s a huge shift.
But there’s a catch:
These fast prototypes often hit a wall when it’s time to scale. You can get something working quickly, but turning it into a reliable production system is a different challenge.
Production brings a new set of rules. If your app has real users and real traffic, you’ll need more than clever hacks. You’ll need solid architecture. That’s when plug-and-play solutions start to show their limits—especially when response time, cost, and reliability matter.
You’re not just writing code anymore. You’re designing systems that:
- Orchestrate AI services instead of just hitting APIs or querying databases
- Handle queues, retries, and fallbacks like any other distributed system
Traditional engineering practices still matter. Event-driven design, message queues, fault tolerance—it’s all still relevant. What’s new is what you’re plugging into those patterns.
So don’t treat AI like magic. Treat it like infrastructure.
Just like you wouldn’t build a web app without understanding HTTP, you shouldn’t build AI features without knowing how the models behave—and where they break.
Prompt Engineering: The New Programming Language
Each LLM has its own “personality”, and those differences show up in the output.
GPT-4o tends to be cautious and verbose. Claude Sonnet is more analytical and focused. Google Gemini is fast but occasionally unpredictable.
These model traits matter. Identical prompts can yield very different results depending on the model. Don’t rely on trial and error! Write prompts that are tailored to the strengths and quirks of the specific model and use case.
Prompting Patterns: From Basics to Advanced Control
At the foundation, you’ll start with zero-shot and few-shot prompting.
- Zero-shot prompting means giving the model just a plain instruction—no examples, no hints. It relies entirely on what the model learned during pre-training. This works well for straightforward queries like fact lookups or classifications. But it often struggles with nuanced or unfamiliar tasks.
- Few-shot prompting adds a handful of input/output examples before the actual question. These examples help steer the model’s format, tone, or reasoning—without retraining. It’s a lightweight way to guide the model, though it does eat into your token limit.
From there, more advanced approaches offer deeper control over the model’s thinking process:
- Chain of Thought (CoT) encourages the model to explain its reasoning step by step. This approach improves accuracy on logic, math, and commonsense tasks. Instead of jumping straight to an answer, the model “thinks out loud.”
- Tree of Thoughts (ToT) takes it further. The model branches into multiple reasoning paths, evaluates them, and backtracks if needed. This mirrors how humans explore solution trees for puzzles, planning, or complex code tasks.
- ReAct (Reasoning + Acting) combines thought and action. The model alternates between internal reasoning and external steps, like calling an API or using a tool. It’s ideal for workflows that involve real-time decisions, such as code execution or navigating a web interface.

Context, Retrieval, and Output Control
Context management is another critical skill. The quality of an AI response often hinges on what context you provide—and how. A few strategies you could rely on are:
- File-based context to supply relevant documents
- Message-based context for handling ongoing conversations
- Database queries to insert structured information into prompts
A simple, high leverage technique is reverse prompting. Instead of guessing what the model needs, just ask:
What information do you need to answer this well?
This collaborative approach reduces ambiguity and often leads to higher-quality results.
Another thing you could do is adopt RAG (Retrieval-Augmented Generation) as part of your default architecture. RAG systems search a knowledge base in real time and inject the results into the prompt. This gives models just-in-time access to the right information, without retraining or fine-tuning (more on this later).
Finally, there’s output control. If your model feeds into a system, you need structured, reliable outputs. That’s where tools like structured prompts, format constraints, and JSON schemas come in. They help ensure that the model’s output is consistent, parsable, and production-ready.
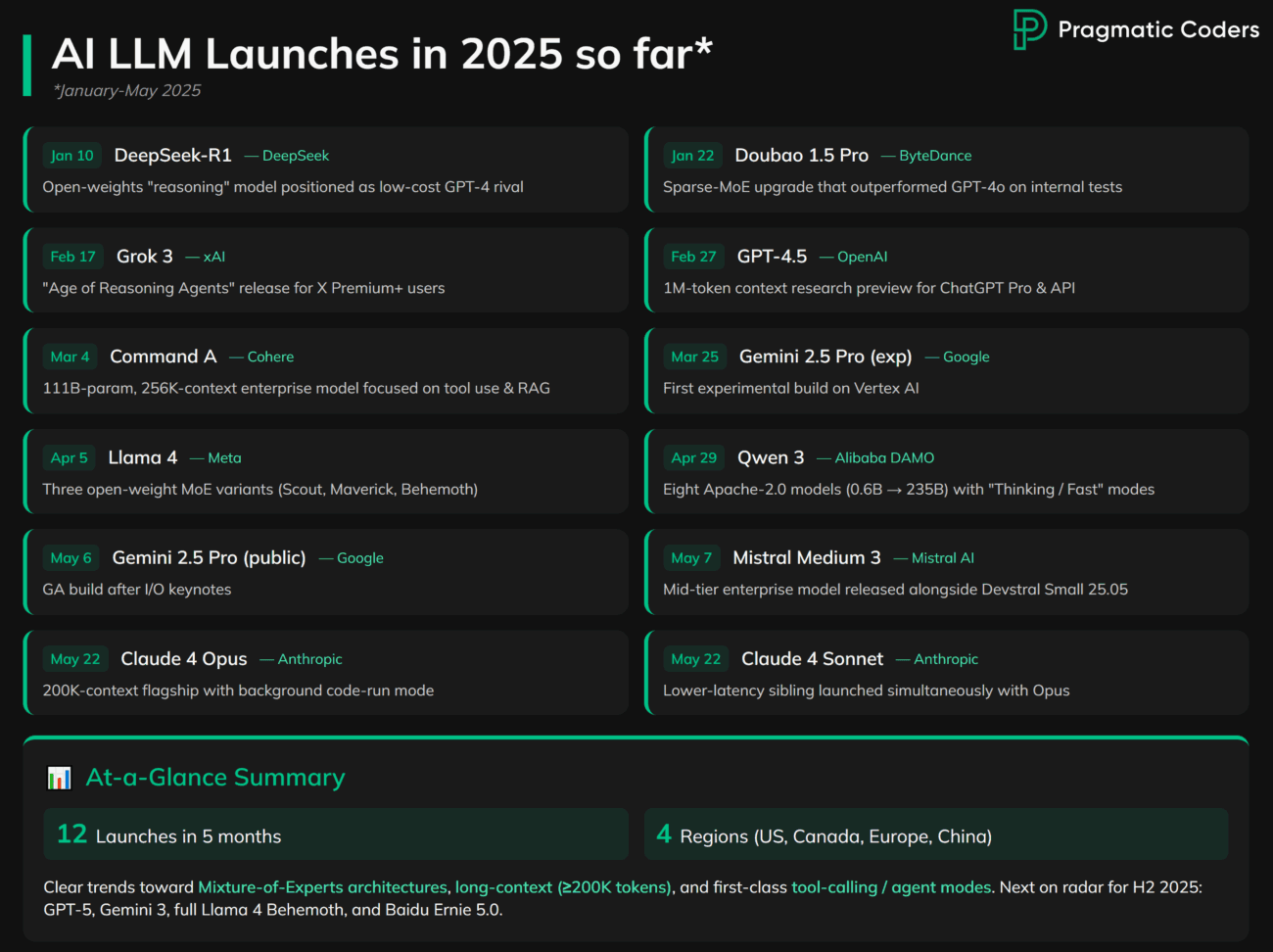
Staying Current with Rapid AI Evolution
The AI landscape moves fast. Really fast.
New models are released almost weekly. Claude’s Sonnet and Opus 4.0 dropped on May 22, 2025—and there’s a good chance something newer is out by the time you’re reading this.
If you wait for blog posts, benchmarks, or vendor comparisons, you’re already behind. Early movers get the edge.
Don’t wait. Test early. The best way to evaluate a new model is to run it against your own use cases, not someone else’s leaderboard.
When testing, don’t just look for speed or style. Focus on what matters:
- Hallucination rates
- For example, based on my own experience, Claude 4.0 Opus hallucinates way more than Sonnet 4.0.
- Reasoning quality
- Obvious failure modes (instruction lapses, context spills, etc.)
AI labs run massive evaluation pipelines before launch. That’s great—but your job isn’t to validate models globally. Your job is to decide if a model fits your specific product or workflow.
Also, remember: newer isn’t always better.
Sometimes an older model like GPT-4o outperforms newer ones—especially on simple tasks. It’s often faster and cheaper, too. Advanced models shine at multi-step reasoning, but they might be overkill for straightforward applications.
Pick the right model for the task.
Balance capability, speed, and cost. That’s how you stay competitive—without over-engineering your stack.
Cost Optimization: The New Performance Metric
When you’re building with AI, cost isn’t just a finance concern—it’s a core part of engineering.
Forget the old benchmarks of speed and memory.
What really matters with AI is the cost-per-request. That one metric reshapes how you design systems, pick models, and structure features.
If you want your product to scale profitably, not just technically, you need to optimize for economic efficiency from day one.
Start with the basics: every API call costs money. That means every design choice should consider call frequency and how to reduce it. You’ve got a few key levers to work with:
- Batch requests whenever possible
- Cache aggressively to avoid redundant queries
- Choose the cheapest model that still meets your quality bar
Model selection is where teams often overspend. You don’t need GPT-4.5-level reasoning for basic tasks. Use lighter models for classification, keyword extraction, or formatting. Save the heavy hitters for the few places that really need them.
Also, lighter models are usually faster. That improves your UX and reduces latency, while keeping costs down. Think of it like choosing a database. You don’t pull in a graph DB for a simple key-value lookup. Don’t default to the most powerful model just because you can.
You also need to plan for what happens when usage scales. Hosted APIs are a great way to start—they’re simple and flexible.
But as traffic grows, so do your costs.
At some point, it may make more sense to self-host. Yes, it’s a bigger upfront investment. But it gives you cost control, predictability, and in some cases, compliance advantages.
Run the numbers. Know your break-even points. Have a migration plan before the bill surprises you.
Testing and Verification: Quality in the AI Age
Modern AI models come with something (relatively) new: self-verification. They can reason through multiple solution paths before responding, kind of like reviewing their own work. This mirrors how you’d do a code review before a commit.
Flagship models like GPT-o3 and Claude 4.0 already use this technique under the hood. It helps catch the obvious mistakes. But here’s the catch: subtle issues still need a human in the loop. You can’t rely on self-verification alone.
Here’s where things get tricky. AI doesn’t just write code—it floods you with it. Thousands of lines can be generated in minutes.
Your job is to keep quality high without becoming the bottleneck.
How? Focus where it matters:
- Deep review for high-impact logic
- Quick scan for boilerplate and obvious patterns
Think of it as trust—but—verify (KGB-style). Verify everything. And verify even more where the risks are higher. Here’s more on secure AI-assisted coding.
Bringing AI into the Testing Loop
AI also helps with testing itself.
You can generate test suites alongside the implementation. The model can verify code structure, anticipate edge cases, and accelerate test coverage. This opens the door to something powerful: test-driven AI-augmented development. You write the specs and tests first, then implement with AI. It keeps your workflow fast but grounded in quality.
But don’t stop there.
You’ll also need to watch for drift—that’s when a model’s behavior changes in production, even if you haven’t changed your code. It can happen for all kinds of reasons: new data patterns, shifts in what “correct” means, or silent updates to the model itself.
One day it works. The next, it starts giving weird or degraded outputs.
To stay ahead of it, build in:
- Output tracking – log representative prompts and responses so you can spot shifts fast
- Performance monitoring – track key metrics like accuracy, latency, and hallucination rate
- Rollback options – keep last-known-good versions ready to restore if something breaks
AI makes you faster. But speed without safety is a risk. Build quality into the loop—from generation through to production.
Infrastructure Decisions: APIs vs Self-Hosting
When you’re starting out, API-first is usually the right move. You get low upfront costs, minimal setup, and the ability to ship fast. For MVPs or low-traffic products, APIs let you focus on building—not managing infrastructure.
But as your app grows, the cracks start to show.
You’ll hit rate limits, notice latency issues, and feel the pain of unpredictable costs, especially if your usage spikes. There’s also the risk of vendor lock-in, which can make future changes harder than they need to be.
That’s when self-hosting starts to make sense. You should consider it when:
- You need tight control over cost and performance
- You’re dealing with large-scale workloads
- You have security or compliance requirements that third-party APIs can’t meet
Self-hosting doesn’t just save money at scale. It gives you full control. You can optimize infrastructure, run custom models, and own the entire AI pipeline end to end.
Often, a hybrid strategy works best:
Use APIs for experiments, low-volume features, or non-critical paths. Use self-hosted infrastructure for core, high-volume, or sensitive workloads. That way, you stay flexible and avoid premature optimization.
The rule of thumb is: start with APIs. Prove the need. Then migrate when the economics and architecture justify it.
Data Strategy and Vector Databases
Traditional machine learning still has a strong role to play. For structured data tasks—like classification, pattern detection, or anomaly spotting—classic ML is often faster, cheaper, and easier to deploy than LLMs. It lacks flexibility, but when you don’t need language reasoning, it gets the job done.
Fine-tuning might seem like the next logical step when base models don’t deliver. But it’s rarely worth it. Training or even fine-tuning a model is expensive, time-consuming, and complex. Unless you’re working in a highly specialized domain, the ROI just isn’t there.
That’s where vector databases come in.
They’ve become a core part of the modern AI stack. Instead of retraining a model every time your data changes, vector databases let you search by meaning, not just by keywords. This powers Retrieval-Augmented Generation (RAG)—a practical way to give models access to up-to-date, domain-specific information at runtime.
With vector databases, you can:
- Run semantic search over large, unstructured datasets
- Inject real-time, relevant context into model prompts
- Avoid retraining while keeping responses accurate and current
RAG helps your AI stay grounded in real data—your data—without the cost and complexity of fine-tuning. If you want your model to know your product, your docs, or your customers, this is how you do it.
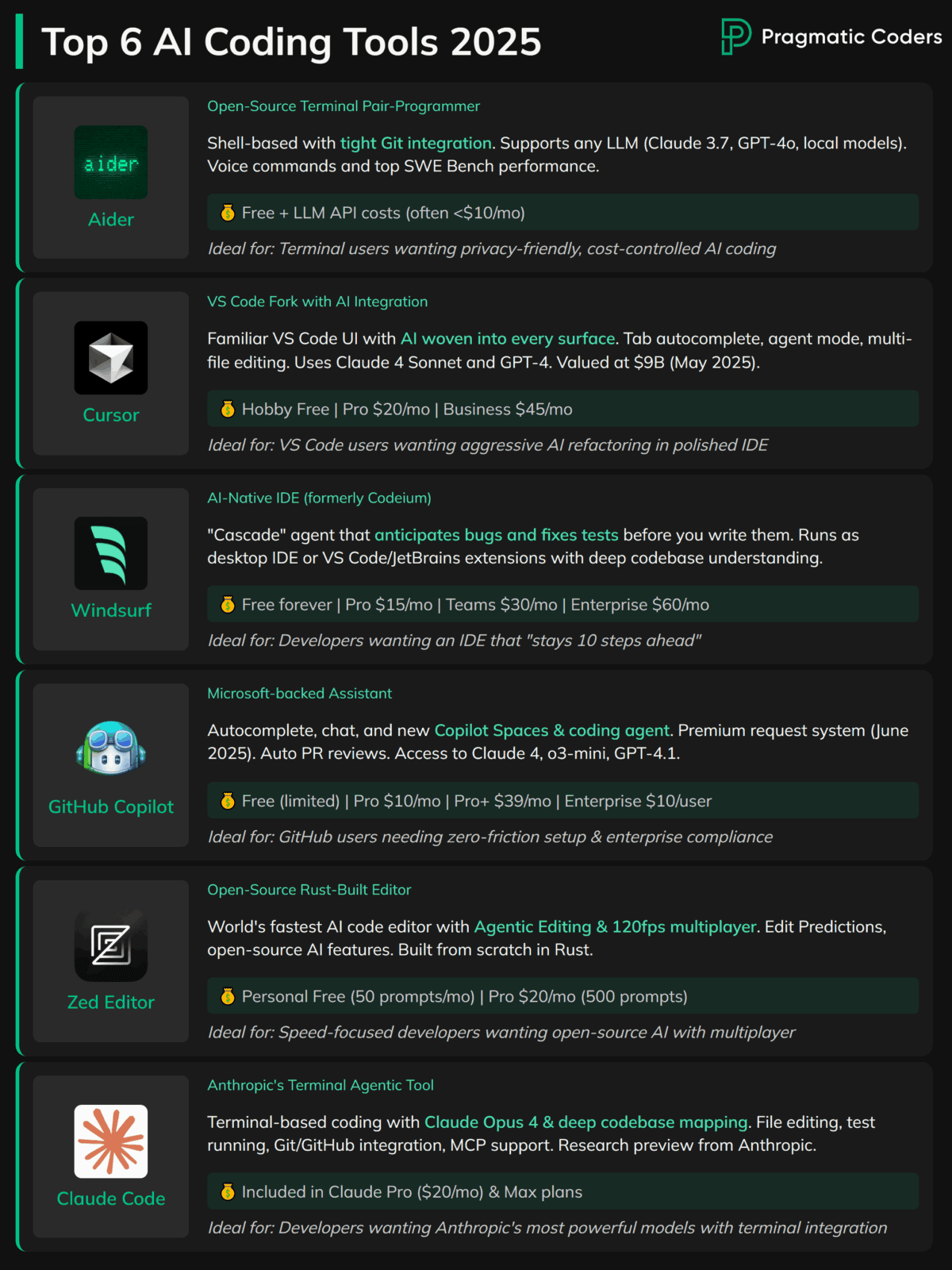
Essential Tools and Continuous Learning
Modern AI-powered dev environments can give you a serious productivity edge. Tools like Cursor and Claude Code, Aider, and GitHub Copilot all help you write, review, and refactor code with AI assistance baked in.
They overlap in what they offer, but here’s what matters: pick one and master it. Real gains come from fluency, not from hopping between tools.
Your tools shape how fast—and how well—you build.
The same goes for APIs. The AI provider landscape changes constantly. OpenAI is still the default for many teams, but it’s not always the right fit.
- Need speed? Google’s models tend to lead.
- Need careful reasoning? Anthropic often does it better.
Understand the trade-offs. Build abstraction layers. That’s how you stay flexible, avoid lock-in, and adapt as the market evolves.
Vector database skills are now table stakes (to a point I’m mentioning it for the 3rd time). Start with a managed service like Pinecone to learn the basics—embedding, querying, similarity search. From there, practice with real data and use cases. This stuff powers retrieval, RAG, and anything that connects models to live information.
Want to know a secret? The field moves too fast — you can’t keep up just by reading.
Make experimentation a habit.
Try new models. Build throwaway prototypes. Play with things that might not work. That’s how you sharpen your judgment and stay ahead, while everyone else is waiting for a tutorial to drop.
Conclusion
AI integration is no longer optional. It’s a core skill—and it’s already separating developers who ship from those who stall. But the goal isn’t to become an AI researcher.
Your job is to become an AI orchestrator—someone who knows how to combine powerful models with solid engineering.
Start small. Pick focused areas. Build real things. That’s how you develop the kind of intuition that docs and demos can’t teach.




