Is Your Logistics Data Digital-Twin Ready? 3 Debts to Fix

A Digital Twin is a derivative asset. In finance, a derivative’s value depends entirely on the underlying asset. If the underlying is junk, the derivative is worthless. The same logic applies to logistics. You can build the most sophisticated Digital Twin on the market, but if it runs on fragmented, stale, or inaccurate data, it will simulate a warehouse that doesn’t exist. Decisions will be made on yesterday’s numbers. The ROI case will collapse within weeks. Before investing in the shiny object, you need to audit your supply chain technical debt.
This article maps the three types of logistics data debt that block Digital Twin readiness. It provides a phased roadmap to fix them without replacing your existing systems.
Key Points
|
Fixing data is step one. Big programs also need clear goals, owners, and metrics. For a fast written check, use the Product Health Checklist.

Why Logistics Digital Twins Fail Before They Start
Most Digital Twin failures trace back to data infrastructure, even when they look like technology problems on the surface.
The visibility gap in logistics is staggering. According to IBM’s Global CSCO Study, 84% of Chief Supply Chain Officers report that lack of visibility is their biggest challenge. IDC research paints an even sharper picture: only 20% of supply chain data is readily available to the people who need it. Of that 20%, less than 10% is effectively used. The other 80%? It’s dark and unstructured, invisible to analytics and simulations alike.
This matters now more than ever. According to Visual Capitalist, 50% of companies that implemented Digital Twins reported returns above 20%. Meanwhile, 74% of surveyed executives expect to increase their spending on digital twins next year. Companies applying AI to supply chains are cutting disruptions in half and reducing expedited shipment costs by up to 50%.
But here’s what happens when you skip the data foundation work. You build a Twin on broken infrastructure. The simulation diverges from reality within days. Planners trust the model, but the warehouse floor tells a different story. Decisions based on flawed data lead to delayed shipments and lost revenue. Once that gap becomes visible, trust in the Twin collapses and the project gets shelved.
Better data and AI can reduce reactive firefighting. If your program still feels unstable—missed dates, shifting scope, constant emergencies—the issue may be deeper than pipes and feeds. Read Is your project on fire? Self-diagnosis.
![Is your project on fire [EBOOK]](https://www.pragmaticcoders.com/wp-content/uploads/2026/02/Is-your-project-on-fire-EBOOK.png)
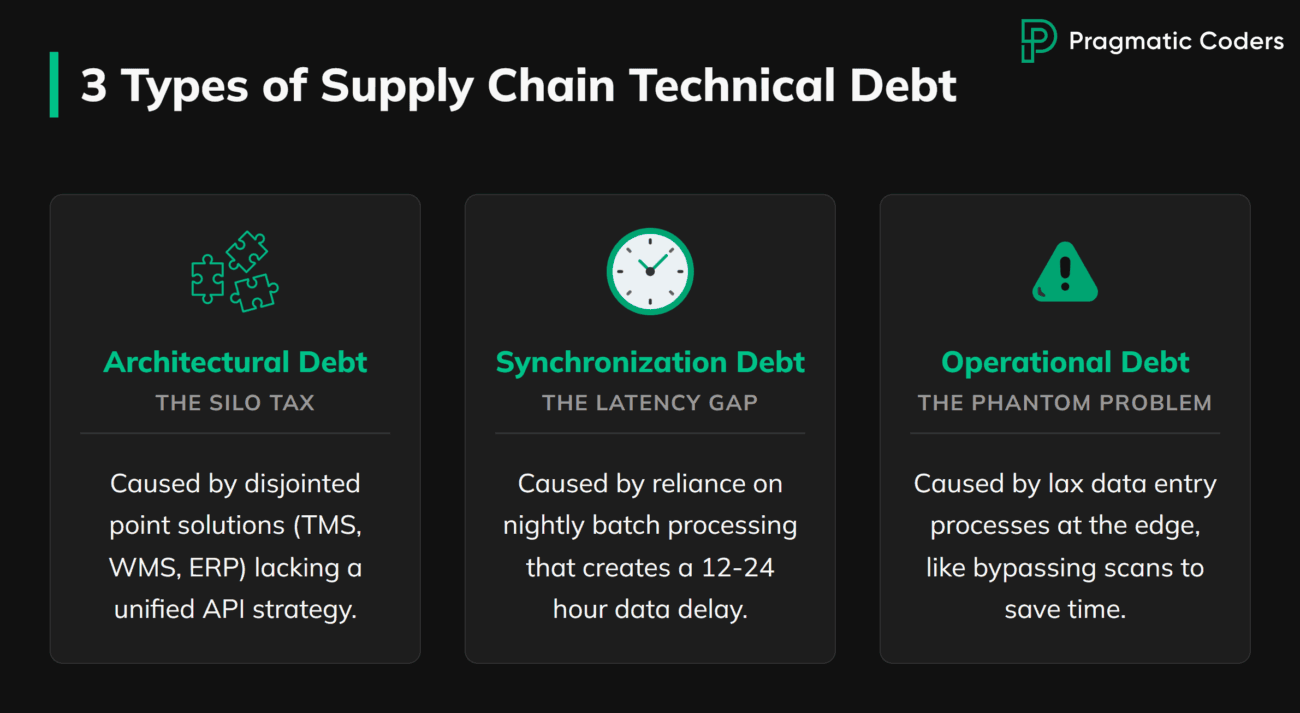
What Causes the Gap: Three Types of Supply Chain Technical Debt
Think of your data problems not as errors, but as debts accrued over years of shortcuts and legacy software choices. Interest compounds daily, and it has a measurable cost.
Three types of debt block Digital Twin readiness:
Architectural Debt: The Silo Tax
This debt comes from years of buying disjointed point solutions. A standalone TMS here. A separate WMS there. A legacy ERP holding it all together with duct tape and zip ties. No unified API strategy connects them.
The cost? You pay “interest” every time you build a manual workaround or Excel bridge to move data between systems. IDC identifies order management as one of the most time-consuming processes in B2B commerce. Fragmented systems force teams to chase order status manually instead of delivering real-time answers. That friction signals architectural debt. A Digital Twin can’t function on manual bridges.
Synchronization Debt: The Latency Gap
This debt comes from reliance on batch processing. Nightly inventory dumps saved compute power and complexity in the past. They create a fatal flaw for Digital Twins.
A Twin requires a live pulse. If your system relies on “end-of-day” batches, your simulation is always 12-24 hours behind reality. The Twin shows 500 units on the shelf. A rush order depletes 300 of them by mid-morning. Your team commits to a delivery they can’t fulfill. By the time the batch runs tonight, the damage is done. Latency turns your Twin from a decision tool into a rearview mirror.
Operational Debt: The Phantom Problem
This debt comes from lax data entry processes at the edge. Forklift drivers bypass scans to save time. Customer service reps use free-text fields instead of dropdowns. Receiving clerks estimate quantities instead of counting.
The result is phantom inventory. The system says you have stock. The shelf is empty. The Twin simulates a warehouse that doesn’t exist.
How to Pay Down the Debt: Phased Logistics System Modernization
A full system replacement is risky, expensive, and often unnecessary. What you need is a phased modernization strategy that wraps around your legacy systems.
Phased modernization costs less upfront and carries lower risk than full replacement. You see incremental value at each phase instead of betting everything on a multi-year migration.
Phase 1: Stabilize
Build the APIs to connect the silos. The core solution here is a middleware bridge: a custom integration layer that sits between your legacy systems and everything that consumes their data. It intercepts “dirty” legacy data, cleans it in real-time, and serves a standardized stream to downstream applications.
In practice, this means deploying an integration layer that uses event-driven architecture or Change Data Capture (CDC) to pull data from legacy systems without modifying them. The middleware normalizes formats: converting proprietary codes to standard identifiers, reconciling units of measure, and timestamping every transaction. A message queue buffers the stream, so downstream systems receive consistent data even when source systems lag or fail.
The outcome is a unified data layer without replacing core systems. You stop paying the silo tax immediately.
Phase 2: Standardize
Enforce data integrity at the edge. Deploy mobile apps for warehouse workers that eliminate free-text fields and scan bypasses. Make the right behavior the easy behavior.
The apps connect directly to your WMS and ERP through the middleware layer built in Phase 1. When a worker scans an item, the system validates it against current inventory records, flags discrepancies, and logs the transaction. No manual reconciliation. No end-of-day batch corrections. Data quality becomes a byproduct of the workflow, not a separate cleanup task.
This phase requires training and process change, not just technology deployment. The outcome is clean data at the source. Phantom inventory starts disappearing.
Phase 3: Simulate
Only now do you build the Digital Twin. With clean, real-time, unified data, the simulation actually reflects reality. You can trust the predictions. You can run scenarios with confidence.
The Twin pulls from the unified data layer built in Phase 1. Every pallet, order, and shipment has a digital counterpart that updates in real time. Run a scenario: a port closure, a demand spike, a carrier going offline. The simulation shows downstream impact across your network in seconds. You’re testing decisions before you make them.
The outcome is accurate forecasting and scenario modeling that drives real decisions.
Phase 4: Scale with AI
Layer AI and ML capabilities on top of the Twin for predictive insights. Smart alerts cut through data noise and predict disruptions before they occur. AI-powered “Resolution Rooms” bring together the right team members with relevant information when issues arise. Digital “playbooks” archive resolutions and recommend actions for similar future disruptions.
Machine learning models train on the historical data flowing through your unified data layer. They spot correlations humans miss: weather patterns that predict carrier delays, order velocity that signals demand shifts, supplier behaviors that precede stockouts. The Twin simulates; the AI anticipates. Together, they move you from reactive firefighting to proactive planning.
The outcome is proactive supply chain management. You’re preventing problems, not just reacting to them.

Digital Twin Success: Companies That Fixed Their Data First
Companies that address data debt before building their Twin see measurable results.
German drugstore retailer dm-drogerie markt created digital twins of each of its 2,000+ stores. Each twin includes shelf layouts and all product SKU locations in every branch. With real-time visibility of product availability across all locations, they optimally combine goods on incoming mixed pallets. They minimize employee in-store walking distances with smartphone-displayed restocking paths. The foundation was real-time visibility at the SKU level across every location. That’s what made the simulation accurate.
Lenovo took a different path but reached the same conclusion. They prioritized connecting disparate data sources before layering on advanced capabilities. Within six weeks, they had a working proof of concept. The lesson: fix the data layer first, then build on top of it.

Conclusion
A Digital Twin is only as valuable as the data infrastructure underneath it. Most logistics organizations carry years of technical debt in siloed systems, batch-processed data, and lax edge processes. Building a Twin on this foundation is building a derivative on a worthless underlying. The model looks sophisticated. The output is junk.
The path forward is a phased modernization strategy. Stabilize your connections. Standardize your data entry. Simulate with confidence. Then scale with AI.
Not sure where your logistics data stands? Contact us for an audit. We specialize in modernizing legacy logistics systems and can help you map your technical debt before you invest in a Digital Twin that’s built to fail.




